AI Consulting
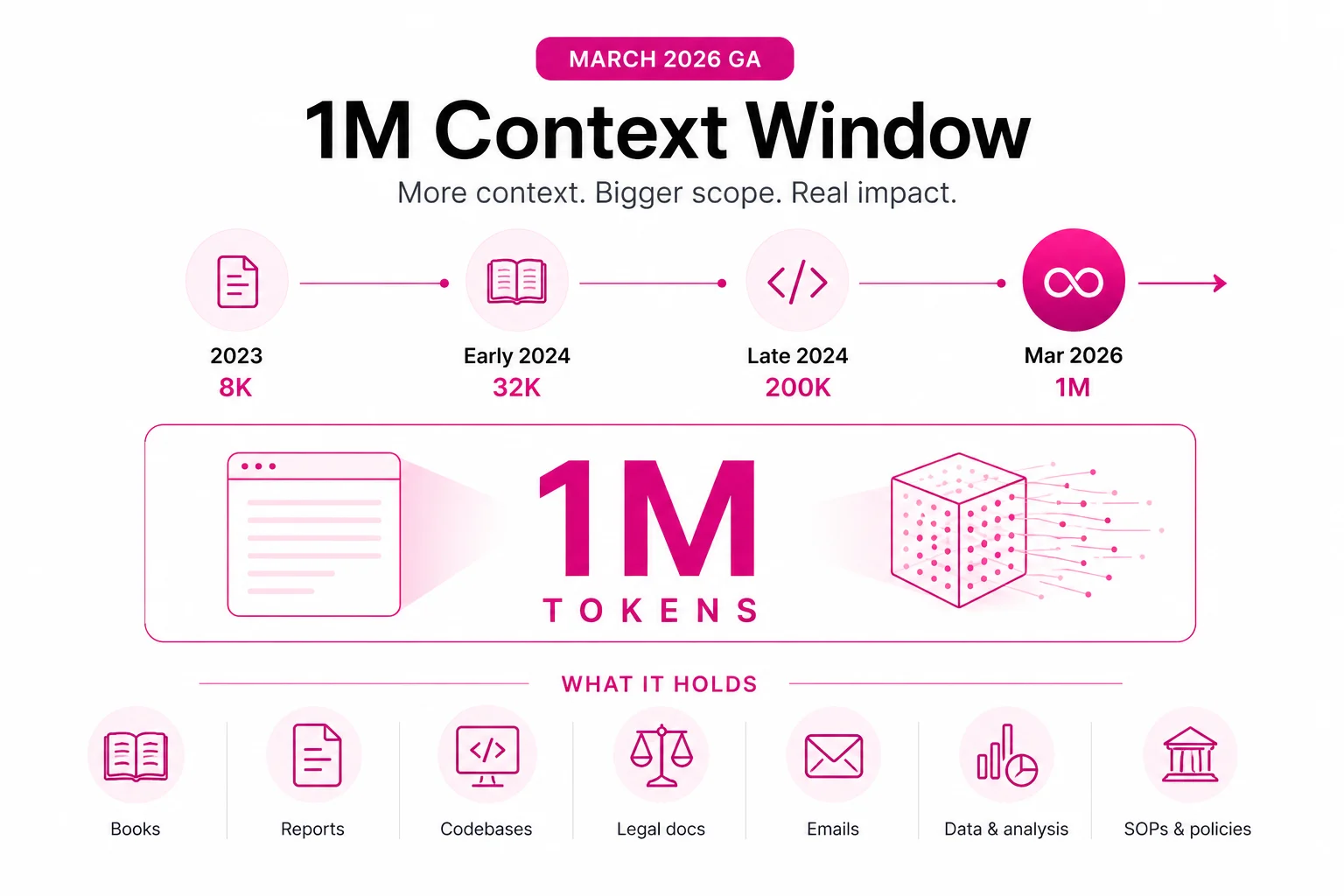
Numbers in AI announcements have a way of sounding impressive while meaning very little to the people who actually have to do something with them. "One million tokens" is one of those numbers. It appears in Anthropic's March 2026 general availability announcement for the 1M context window — and most enterprise leaders see it, nod, and move on without a clear picture of what has actually changed.
What has changed is significant. The 1M token context window, now generally available for Claude Max, Team, and Enterprise users, is not a developer feature dressed up as a business announcement. It is a fundamental shift in what a single AI session can encompass — and therefore in the scope of problems that can be solved without custom engineering. Here is what it means in practice.
Every interaction with a large language model has a limit on how much information it can "hold in mind" at once. This is the context window: the total number of tokens — roughly equivalent to words and word fragments — that the model can process in a single session. Within that window, the model can reason across everything: your question, the documents you have provided, the conversation history, the instructions you have given it.
Outside that window, the model has no memory. If your document is longer than the context window, the model cannot read the whole thing. If your conversation history exceeds the limit, earlier parts are forgotten. The context window is the model's working memory, and its size determines what kinds of work are tractable.
The progression over the past two years shows why the March 2026 GA milestone matters:
| Year | Context window | What fit in it |
|---|---|---|
| 2023 | 8,000 tokens (~6,000 words) | A few pages of text, short documents |
| Early 2024 | 32,000 tokens (~24,000 words) | A short book, a quarterly report |
| Late 2024 | 200,000 tokens (~150,000 words) | A full book, a large codebase |
| March 2026 | 1,000,000 tokens (~750,000 words) | An entire codebase, a legal library, years of records |
To make this concrete, here is what fits comfortably within a 1M token context window:
Previously, AI-assisted code review required selecting which files to include — a judgment call that determined whether the AI saw the relevant context. At 1M tokens, the entire codebase goes in. Claude can identify patterns across files, find the source of a bug that spans three modules, suggest a refactoring that requires changes in fifteen places, and do so with awareness of every dependency that would be affected.
For Indian software teams managing legacy codebases — applications written over five to ten years, with accumulated technical debt and inconsistent patterns — this is transformative. A full codebase audit that previously required a team of engineers weeks can now be completed as an AI session.
Legal teams at Indian enterprises typically review contracts one at a time. When a vendor negotiates a new agreement, the reviewer checks it against the standard template and flags deviations — but rarely has the time to cross-reference it against every other active vendor contract. At 1M tokens, the entire active contract library can be in context. "Does this new agreement with Vendor A conflict with any exclusivity provisions in our existing contracts?" is a question Claude can now answer with access to all of them simultaneously.
Audit preparation in Indian enterprises involves compiling hundreds of documents across multiple systems — vouchers, bank reconciliations, fixed asset registers, statutory filings, board minutes. At 1M tokens, the complete set of supporting documents for an audit period can be loaded. Claude can perform completeness checks, identify missing items, flag inconsistencies between documents, and draft the management discussion section with reference to the actual numbers.
AI-powered customer relationship tools have been limited by context: they can see recent interactions but lose the thread of long-term relationships. At 1M tokens, the full history of a key account — every interaction, every support issue, every purchase, every escalation — is accessible in one session. This changes the quality of AI-generated account reviews, renewal risk assessments, and expansion recommendations.
The honest caveats deserve equal space. Longer context windows increase the cost per call proportionally — loading 1M tokens costs significantly more than loading 10,000 tokens. For applications where you pay per token, this matters. The right approach is to use the full window for tasks where it genuinely requires the full context, not as a default for every interaction.
Latency also increases with longer context. A 1M token session takes longer to process than a 100K token session. For real-time applications where response speed is critical, the full 1M window may not be appropriate. For batch analysis tasks — overnight audit preparation, weekly contract reviews, monthly code analysis — latency is irrelevant.
Accuracy at very long contexts is an area of active improvement. Claude performs well on retrieval and reasoning tasks within 1M tokens, but like any cognitive system, performance on very specific details at the far end of a very long document can be less reliable than at shorter lengths. For critical decisions based on specific clauses or specific data points, human verification of the AI's conclusions remains important.
The 1M token window changes the architecture of enterprise AI applications. Features that previously required a retrieval-augmented generation (RAG) pipeline — with its complexity, latency overhead, and risk of missing relevant context — can now be built as direct context injection for many use cases. Simpler architecture, faster development, better results for tasks that benefit from complete context.
Our AI Builder service incorporates long-context Claude where the use case benefits from it — full codebase analysis tools, complete document review applications, comprehensive customer intelligence systems. Our technology services team helps enterprise architects redesign existing AI applications to take advantage of the expanded window where it delivers measurable value.
For workflows involving large document collections — contract analysis, audit preparation, regulatory compliance — our data pipeline services handle the pre-processing that gets your documents into the context efficiently. And our strategic consulting team can assess which of your current or planned AI use cases benefit most from the 1M token window and prioritise accordingly.
The number is 1 million. What it means is: the limiting factor for enterprise AI is no longer the size of the context. It is the clarity of the question. Talk to our team about what that opens up for your organisation.