AI Updates
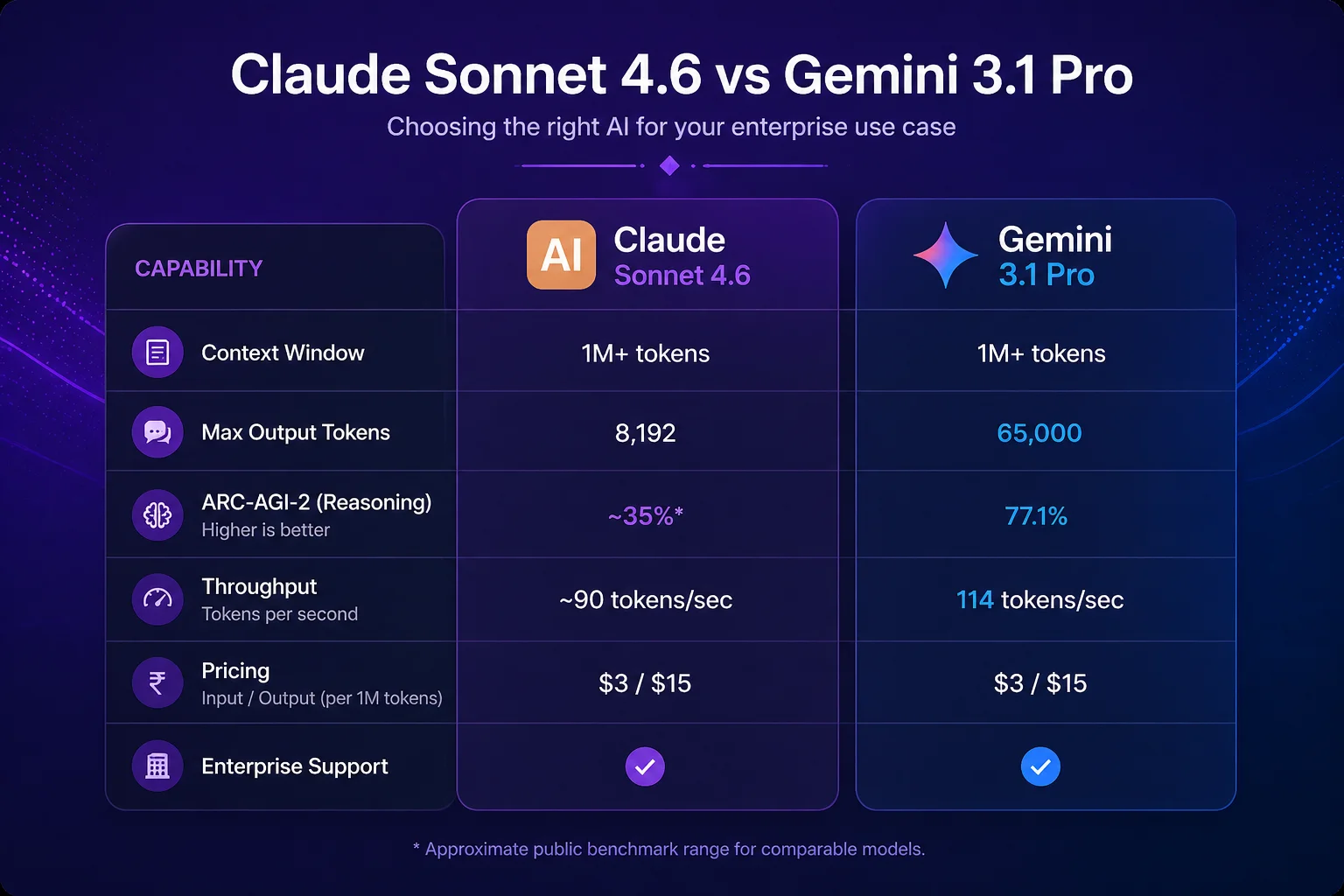
In January 2026, the question Indian enterprise AI teams asked most was "should we use AI?" By February, the question had shifted: "which AI should we use?" Both Claude Sonnet 4.6 and Gemini 3.1 Pro now sit in the same capability tier — world-class reasoning, comparable pricing, 1M+ token context windows, and strong enterprise support. The choice between them is no longer "better vs. worse." It is "better for which use case."
Gemini 3.1 Pro landed on February 19, 2026 with a specific set of improvements that directly challenge Claude's position in enterprise deployments. Here is a clear-eyed comparison of the two models, built around the actual use cases Indian enterprises are deploying today.
Google's Gemini 3.1 Pro makes significant gains over its predecessor. The headline numbers: 1M token context window (matching Claude Sonnet 4.6), 65,000 token output limit — the highest of any production frontier model — 77.1% on ARC-AGI-2 (double Gemini 3 Pro's score), and 114 tokens per second throughput. Pricing stays flat at the same rate as Gemini 3 Pro.
The 65,000 output token limit is the standout feature. Claude Sonnet 4.6 caps at 8,192 output tokens per request. For applications that need to generate long documents — detailed financial reports, comprehensive technical specifications, full contract drafts, extended code files — Gemini 3.1 Pro's output capacity is a material advantage.
The ARC-AGI-2 benchmark tests novel reasoning — the ability to solve problems the model hasn't seen before, requiring genuine generalisation rather than pattern matching. Doubling performance on this benchmark in a single generation is significant. It suggests Gemini 3.1 Pro has meaningfully improved at handling unusual or edge-case reasoning tasks.
| Benchmark / Capability | Claude Sonnet 4.6 | Gemini 3.1 Pro | What it measures |
|---|---|---|---|
| MMLU (knowledge breadth) | 92.3% | 91.8% | General knowledge across domains |
| SWE-bench Verified (coding) | 70.3% | 61.2% | Real-world software bug resolution |
| ARC-AGI-2 (novel reasoning) | ~62% | 77.1% | Solving genuinely new problem types |
| Context window | 1M tokens | 1M tokens | Max input length |
| Max output length | 8,192 tokens | 65,536 tokens | Length of single response |
| Throughput | ~85 tokens/sec | 114 tokens/sec | Response generation speed |
The takeaway from the benchmarks: Gemini 3.1 Pro leads on raw output volume and novel reasoning. Claude Sonnet 4.6 leads on software engineering tasks. They are comparable on general knowledge. Neither dominates across every dimension — which is exactly why the use-case framework below matters.
If your application needs to generate documents longer than roughly 6,000 words in a single API call — detailed audit reports, comprehensive legal agreements, full technical documentation — Gemini 3.1 Pro's 65K output limit makes it the practical choice. Claude requires breaking long generation tasks into multiple API calls, which adds engineering complexity and risks inconsistency across segments.
For agentic workflows where the model needs to reason about which tools to call, in what order, and how to handle unexpected intermediate results, Claude Sonnet 4.6 is consistently more reliable. Its tool-use behaviour is more predictable, its refusals are better calibrated (it knows when to ask for clarification rather than guessing), and its instruction following in complex multi-step tasks is stronger.
The SWE-bench gap (70.3% vs 61.2%) is large enough to matter in production. For any application where the AI is generating, reviewing, or debugging code — CI/CD automation, code review bots, technical documentation — Claude Sonnet 4.6 produces fewer hallucinated APIs, better security awareness, and more consistent code style adherence.
Gemini 3.1 Pro's vision capabilities are stronger for complex image understanding tasks — document scanning, diagram interpretation, visual data extraction. For Indian enterprises processing scanned invoices, physical forms, or image-heavy compliance documents, Gemini 3.1 Pro's multimodal performance makes it the more capable option.
For organisations already on Google Workspace (Gmail, Drive, Docs, Sheets, Meet), Gemini 3.1 Pro integrates natively. If your use case is essentially AI-enhanced productivity within Google's ecosystem, Gemini is the natural choice — the integration depth exceeds what any third-party Claude integration can provide through Google Workspace add-ons.
Anthropic's published model specification — 23,000 words detailing Claude's values, refusal behaviour, and handling of sensitive information — gives regulated enterprises in BFSI, healthcare, and government a documented governance foundation. For compliance officers who need to demonstrate AI vendor governance to regulators, this documentation is a material differentiator.
Both models are priced comparably. At 10 million tokens per day — a moderate-volume enterprise application — the difference in API costs between the two models is small enough that it should not drive the decision. Architectural fit and output quality for your specific use case matter far more than a 15–20% pricing difference at similar capability levels.
Where pricing becomes relevant is at very high volumes (100M+ tokens/day) or when factoring in the cost of engineering time to work around a model's limitations. If Gemini's 65K output limit saves you a complex chunking-and-stitching implementation, that engineering saving easily outweighs any token pricing difference.
The pattern that emerges across mature enterprise AI deployments is predictable: teams start with one model, discover specific use cases where the alternative performs better, and end up running both. Gemini 3.1 Pro for long document generation and multimodal processing. Claude Sonnet 4.6 for agentic tasks, code-heavy workflows, and regulated-industry deployments. Claude Haiku 4.5 for high-volume preprocessing.
The risk of this multi-model approach is operational complexity: different API clients, different prompt styles, different safety behaviours, different failure modes. Managing this well requires an abstraction layer that routes requests to the appropriate model based on task type, monitors performance across models, and handles failover.
Infurotech's AI Builder service is built to be model-agnostic by design — we select the right model for each component of an application and manage the routing logic as part of the platform. Our technology services team can help your architecture team design a model strategy that doesn't create vendor lock-in and doesn't require your application teams to become AI researchers.
If you want a structured assessment of which model strategy fits your current AI applications and planned roadmap, our strategic consulting team can deliver that in a two-week engagement. Reach out to start the conversation.