Llama 4 Scout & Maverick: What Meta's Open-Source AI Means for Enterprise Deployments
For most of 2024 and 2025, the practical question for enterprises evaluating AI was simple: use a frontier model from Anthropic, OpenAI, or Google, or accept a meaningful performance gap in exchange for the cost and control benefits of open-source. In April 2026, Meta closed that gap in a significant way. Llama 4 Scout and Llama 4 Maverick arrived with benchmark performance that competes directly with GPT-4o and Gemini 2.0 Flash — and both are open-weight models that can be deployed on your own infrastructure. For Indian enterprises navigating data privacy requirements, cost pressures at scale, and data sovereignty regulations, this matters more than any individual benchmark score. Here is how to think about what Llama 4 actually changes.
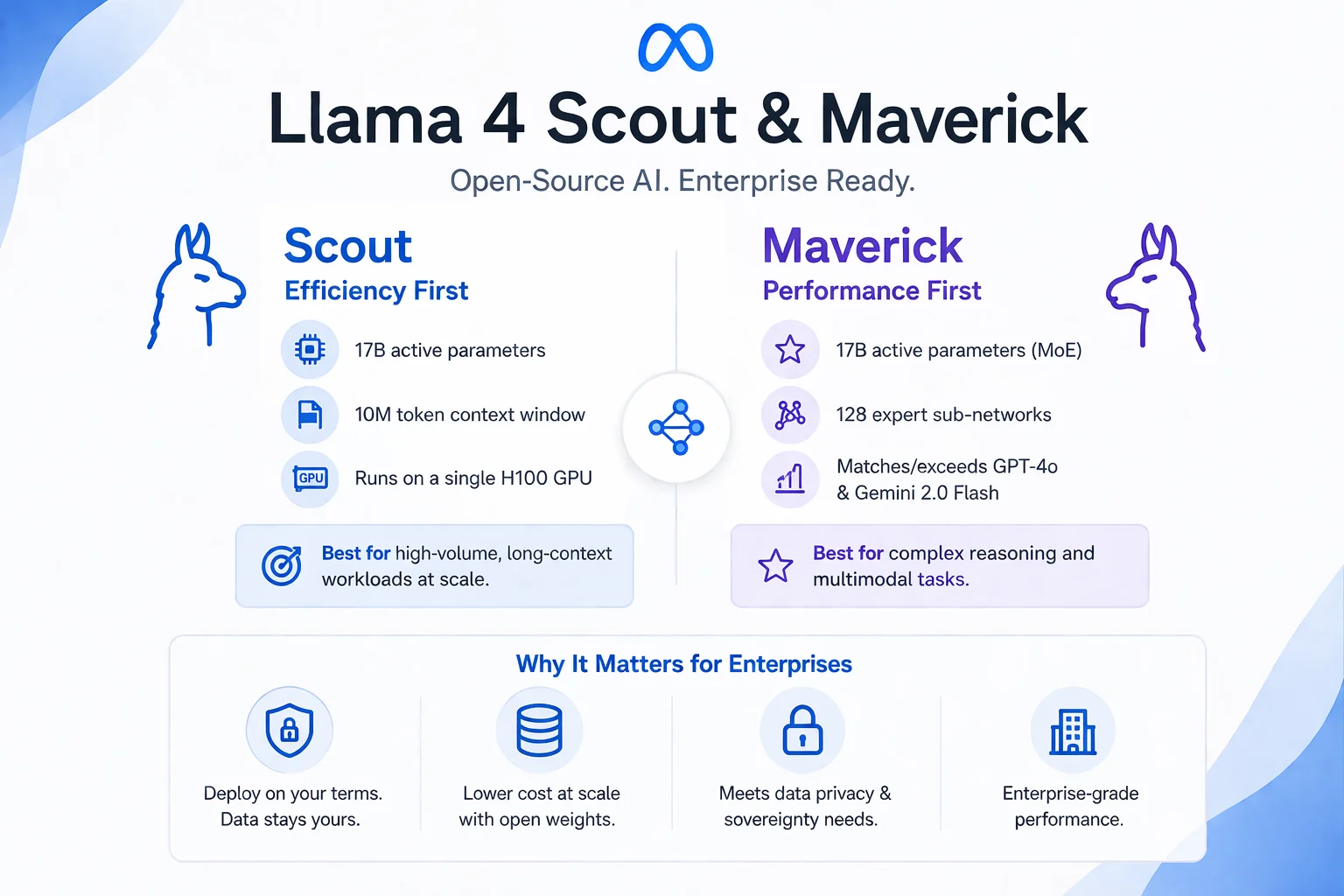
Scout vs. Maverick: Which Model Does What
The two models serve different positions in an enterprise deployment architecture, and conflating them leads to poor decisions about which to use where.
Llama 4 Scout is the efficiency-first model. It carries 17 billion active parameters and runs on a single H100 GPU — a meaningful operational constraint, since it means you do not need a multi-GPU cluster to serve it in production. Scout's defining technical feature is its context window: 10 million tokens. That is not a typographical error. Ten million tokens is the largest context window available in any open-weight model as of this writing, and it is larger than the context windows offered by most frontier models. Scout's intended use is workloads where the volume of text to be processed per request is extreme — long document analysis, large-scale log processing, codebase-level reasoning — and where inference cost per token matters.
Llama 4 Maverick is the performance-first model. It also runs 17 billion active parameters, but it does so via a Mixture-of-Experts architecture with 128 expert sub-networks. On broad multimodal benchmarks, Maverick matches or exceeds GPT-4o and Gemini 2.0 Flash. This is the model you reach for when task complexity matters more than raw throughput — nuanced text generation, multimodal reasoning, tasks where quality of output is the primary metric. Maverick requires more compute than Scout to serve, but it is still deployable on infrastructure that most enterprise AI teams already operate.
The MoE Architecture: Efficiency Without the Obvious Trade-Offs
Mixture-of-Experts is worth understanding because it reshapes how you think about the cost-performance curve for large models. In a standard dense model, every parameter participates in processing every token. A 70B dense model activates all 70B parameters for every forward pass. In a MoE model like Maverick, the total parameter count is distributed across many specialised expert sub-networks, but only a small subset of those experts — the ones most relevant to the current input — are activated for any given token. Maverick has 128 experts but activates 17B parameters per token, not the full combined weight of all experts.
The practical result is that you get a model with the reasoning capability that typically requires a much larger dense model, at the inference cost of a 17B model. This is why Maverick can compete with GPT-4o on benchmarks while remaining deployable on hardware that would not come close to running a 70B dense model at production latency.
The trade-off that MoE introduces is less about raw performance and more about deployment complexity. MoE models can exhibit uneven expert utilisation under certain input distributions, which complicates load balancing in high-throughput serving environments. For most enterprise deployments, this is a manageable infrastructure concern, not a blocking one — but it is worth factoring into your serving architecture design before you go to production.
Scout's 10M Token Context: What It Actually Enables
Context window size determines what a model can reason over in a single inference call. At 10 million tokens, Scout can process approximately 7,500 pages of text in one pass — a volume that covers entire contract portfolios, multi-year transaction histories, or complete software repositories. The operational implications for certain enterprise use cases are significant.
Consider a compliance review workflow where an analyst needs to check a large transaction dataset against a complex regulatory framework document. With a 128K or 200K context window, this requires chunking the data and making multiple inference calls, then synthesising the results — introducing latency, cost, and the risk of losing cross-chunk context. With a 10M token window, the entire dataset and the full regulatory document can be presented to the model in a single call, enabling it to reason over the complete picture simultaneously.
The same logic applies to codebase analysis, where understanding the impact of a change may require the model to have visibility into hundreds of files simultaneously, or to due diligence workflows in M&A where the document corpus runs into thousands of pages. Scout's context window does not make these tasks easy — model reasoning quality still matters — but it removes a structural constraint that has forced architecturally awkward solutions for two years.
When Open-Source Beats Frontier Models
The honest answer is: it depends on your specific operational constraints, not on benchmarks alone. Llama 4 being competitive with GPT-4o on benchmarks does not automatically make it the right choice for every workload. But there are four scenarios where open-weight models now have a compelling structural advantage.
On-Premise and Private Cloud Deployments
Some enterprise workloads — particularly in defence, government, regulated financial services, and healthcare — cannot be processed by a third-party model API under any contractual arrangement. The data simply cannot leave the organisation's infrastructure. Until Llama 4, running a truly capable model in this environment meant accepting a meaningful quality ceiling. With Maverick performing at GPT-4o levels, the quality ceiling is largely gone. Enterprises with genuine air-gap or private cloud requirements can now deploy frontier-competitive intelligence without a cloud dependency.
High-Volume, Cost-Sensitive Workloads
At the token economics of frontier model APIs, certain high-volume use cases — processing every customer support ticket, analysing every inbound document, summarising every call recording — are not financially viable. Open-weight models, once deployed on your own infrastructure, have a marginal inference cost that is effectively the compute cost of your hardware, amortised over all requests. For workloads processing millions of tokens per day, the economics of self-hosted Llama 4 versus frontier API calls are not comparable — the self-hosted option is typically an order of magnitude cheaper at scale.
Data Sovereignty and Indian Data Residency
India's evolving data protection framework under the Digital Personal Data Protection Act creates residency and processing obligations for personal data that are difficult to satisfy when inference is happening on servers in US or European data centres. A self-hosted Llama 4 deployment running in an Indian cloud region or on-premise in India satisfies data residency requirements that a frontier model API call to a non-Indian endpoint does not. As regulatory enforcement matures over 2026 and 2027, this consideration will move from a forward-looking concern to an active compliance requirement for enterprises handling Indian consumer data.
Fine-Tuning on Proprietary Data
Open-weight models can be fine-tuned. Frontier models, in most cases, cannot — or can only be fine-tuned through a managed process that still routes your training data through a third party's infrastructure. Enterprises with large proprietary datasets — internal knowledge bases, historical transaction data, domain-specific document corpora — can fine-tune Llama 4 to produce a model that is specifically adapted to their terminology, reasoning patterns, and output formats. A fine-tuned open-weight model can outperform a generic frontier model on specialised tasks by a substantial margin, even when the base model is less capable.
When Frontier Models Still Win
Llama 4's benchmark performance is real, but benchmarks measure specific, well-defined tasks. There are operational categories where frontier models retain a practical advantage that Indian enterprises should not underestimate.
| Capability | Llama 4 (Open-Weight) | Frontier Models (Claude, GPT, Gemini) |
|---|---|---|
| Agentic reasoning and multi-step tool use | Improving, but behind frontier | Strong — purpose-optimised |
| Complex instruction following | Competitive on benchmarks | More reliable on edge cases |
| Managed uptime and SLAs | Self-managed — your responsibility | Vendor-managed, contractual SLAs |
| Safety and alignment | Base model — requires your guardrails | Extensive built-in safety layers |
| Deployment complexity | Significant — serving, scaling, monitoring | Zero — API call |
| Fine-tuning on proprietary data | Full access, on your infrastructure | Limited or third-party managed |
For agentic deployments — agents that reason over multiple steps, use tools, and make decisions with real-world consequences — frontier models like Claude remain the stronger choice in 2026. The training investment Anthropic has made in agentic reasoning, tool use reliability, and instruction following at the edge cases of complex tasks translates into fewer failures in production. An agent that halluculates a tool call or fails to follow a complex conditional instruction in a high-stakes enterprise workflow is worse than no agent at all. When the cost of an error is high, the quality margin between a purpose-optimised frontier model and a general open-weight model matters in ways that benchmarks do not fully capture.
The operational overhead of self-hosting also deserves honest accounting. Running Llama 4 Maverick in production means owning the serving infrastructure, building your own monitoring, handling model versioning and updates, and managing the GPU fleet that serves inference traffic. For an enterprise with a mature ML platform team, this is standard work. For a team that is new to model serving, the initial deployment cost and ongoing operational burden can erode the economic advantage of open-weight models significantly.
The Multi-Model Strategy: Llama 4 for Volume, Claude for Reasoning
The most sophisticated enterprise AI architectures in 2026 are not single-model stacks. They are multi-model pipelines that route each task to the model best suited to it — optimising for cost on high-volume, lower-complexity tasks while reserving frontier model calls for the steps where reasoning quality is genuinely critical.
A practical example: a customer support automation pipeline might use Llama 4 Scout to classify inbound tickets, extract structured data from customer messages, and generate first-draft responses for common query types — tasks that run at high volume and where a capable open-weight model performs well. For tickets that require nuanced reasoning, policy interpretation, or sensitive handling, the pipeline routes to Claude. The result is a system that handles the majority of volume at significantly reduced token cost, while maintaining frontier-quality outputs for the cases that actually require it.
This routing logic — deciding which tasks go to which model, and building the infrastructure to execute that routing reliably — is where the real engineering and strategic work lives. Llama 4's arrival does not simplify this decision; it makes the decision space more complex and potentially more valuable. The right model mix for a given enterprise workflow depends on the volume, the acceptable error rate, the data handling requirements, and the cost sensitivity of that specific use case. There is no universal answer, and any vendor that offers one without first understanding your workflows should be treated with scepticism.
How Infurotech Helps Enterprises Select and Deploy the Right Model Mix
Model selection is a technical decision with significant business consequences, and it is one that changes as models evolve. A choice that was correct six months ago — before Llama 4's release — may warrant revisiting today. Our AI model strategy consulting engagements are designed to help enterprises make this decision with rigour: mapping your specific workloads to model capabilities, modelling the cost and performance trade-offs, and producing a model selection framework that holds up as the landscape continues to shift.
On the deployment side, self-hosting Llama 4 in a production environment is not a weekend project. Our AI model deployment and fine-tuning services cover the full stack: infrastructure provisioning, serving optimisation, fine-tuning on your proprietary data, monitoring and evaluation pipelines, and the integration work that connects the model to your enterprise systems.
For enterprises building AI-powered products and internal tools, Infurotech's AI Builder practice uses the right model for each task — combining open-weight models for cost-sensitive, high-volume workloads with frontier models for the reasoning-intensive steps that drive business value. For Llama 4 deployment in high-volume automation workloads, we have production experience with the serving infrastructure and prompt engineering patterns that make open-weight models reliable at scale.
The open-source AI landscape has fundamentally changed. GPT-4o-level performance is now available in a model you can deploy on your own infrastructure, in your own data centre, in India. The question for enterprise leaders is no longer whether open-weight models are good enough — for many workloads, they clearly are. The question is how to integrate them into a coherent, cost-optimised AI architecture alongside the frontier models that continue to earn their place for complex, high-stakes tasks. Talk to us about building that architecture for your organisation.